Dès lors que l’on commence à développer dans une équipe de quelques personnes en pratiquant les code reviews, de nombreux problèmes peuvent apparaître. L’exemple le plus fragrant est qu’il se produise des échanges interminables entre le ou les développeurs et les code reviewers. Voyons quels types de problèmes peuvent apparaître, et surtout, comment nous avons résolu ces problèmes chez Brouette-Labs grâce au Jira Driven Development.
Les problèmes
Nous avons identifié deux problèmes majeurs dans notre cycle de code review, qu’on vous propose de retrouver ci-dessous.
Conventions de nommage de code
C’est le problème majeur de tous développeurs. C’est le problème majeur de toutes les codes review. On le connaît tous. Nommer ses fonctions, ses méthodes, ses classes et ses variables peut parfois être un vrai casse-tête, dès lors que le métier est compliqué. D’autant que tous les développeurs n’ont pas les même habitudes créant ainsi des tensions au sein des équipes lors des code reviews.
Gilles [Le prénom a été changé, NDLR], a accepté de témoigner sous couvert d’anonymat de son expérience :
Brouette-Labs : Quelle a été votre pire expérience en terme de conventions de nommage au sein d’une équipe ?
Gilles : Je me souviens très bien d’une mission effectuée au sein d’un grand groupe. On avait deux microservices l’un gérait toute la partie utilisateur et l’autre orienté logistique pour l’émission de colis, dans laquelle on gérait les différentes adresses qu’un utilisateur pouvait avoir. Bien entendu les base de données étaient séparées. Et nous devions pouvoir gérer les adresses également depuis le premier microservice, tout au moins les référencer. Donc dans notre objet User, nous avions les ID’s des différentes adresses stockées elles dans le base de données liée au microservice logistique. Déjà j’ai perdu environ 2h30 à me questionner pour savoir comment nommer ma variable. Devait-elle s’appeler
addressesId,addresseIds, ou encoreaddressesIds. Vous en pensez-quoi vous ?B-L : Je ne sais pas,
addressesIds, la troisième donc ?G. : Oui on est d’accord.
B-L : Vous aviez réellement besoin de réfléchir 2h30 pour cela ?
G. : C’est-à-dire qu’on essaie de travailler proprement tout de même, il est important de prendre soin du nommage. Je pensais cette histoire terminée jusqu’à faire une PR [Pull Request, NDLR].
B-L : Vous pouvez développer ?
G. : Oui, c’était un de mes collègue, pour ne rien vous cacher un vrai grammar-nazi du code. Il voulait que je renomme ma variable en
addresseIdsdonc addresse au singulier pour coller au fait que l’on parle de la ressource. Dans cette PR, il m’a fait différents retours pour autant de choses insignifiantes. L’échange sur github à donc duré pas loin d’une semaine. D’autre part, j’avais la pression de ma hiérarchie et de l’équipe Produit qui attendaient que cette feature passe en production donc que la PR soit mergée au plus vite. Des exemples comme celui-ci j’en ai beaucoup. C’est très frustrant.
Comme vous pouvez le voir dans cette succincte interview, la tension peut aisément se développer dans un tel contexte. Et nous ne parlions avec Gilles que du simple nommage d’une variable, le problème est le même pour tous les types de nommage : classe, méthodes, etc.
Convention de nom des commits
Un peu plus fourbe, les conventions de commit. Faut-il suivre le sacro-saint manifeste d’AngularJS, ou alors est-il mieux de créer sa propre norme.
Qu’est-ce qu’un fix, qu’est-ce qu’un hotfix même. Comment faire lorsque le scope est trop large car il a été mal découpé en amont. Autant de questions auxquelles nous avons déjà été confronté chez Brouette-Labs de part nos expériences passées.
captainjaja nous raconte :
Une fois j’ai fait une PR, qui a été rejected parce que j’avais mispelled un mot dans un commit, j’avais écrit
fix: typoesau lieu defix: typossur un blog concurrent de celui-ci.
Cela peut sembler discriminatoire, nous n’avons pas tous un Bescherelle version anglaise à portée. Quand bien même cela existerait, les gens n’utilisent déjà pas le Bescherelle français. Il en va de même pour les dictionnaires et les livres de grammaire.
Mettre une description dans un commit est donc tout un art.
Convention de nom des branches
Une technique très peu documentée, et souvent laissée de côté. Pourtant il est important de bien nommer ses branches pour avoir un scope clair de ce qui a été fait.
Nous avons pu mettre la main sur un témoignage poignant, anonymisé encore une fois, d’une personne que nous appellerons Antoine.
Brouette-Labs : parlez-nous un peu de votre parcours Antoine.
Antoine : je suis développeur fullstack PHP, Python, ASP, Go, NodeJS, VueJS, ReactJS, ReactNative, Android, iOS depuis bientôt 25 ans. En parallèle je suis également devOps et Sys admin. J’occupe mes soirées et Week-Ends à parfaire mes connaissances du cloud en général AWS, GCP & Azure.
B-L : vous avez en effet un profil assez complet et une expertise non négligeable. Qu’est-ce que vous pouvez nous dire des conventions de nommage des branches ?
A : c’est avant tout du feeling. Je préfixe toute mes branches de la catégorie dont relève le domaine étudié. “sys/” pour l’admin-sys, “ops/” pour tout ce qui concerne le devops. Ensuite je repréfixe d’uune seconde catégorie pour le champs global de la modification apportée. Ça peut être “doc/”, “hotfix/”, “fix/” ou “feat/”. Enfin, ce sur quoi la modification est apportée, un description succincte et sluguée.
B-L : votre méthode a l’air éprouvée, néanmoins qu’est-ce qui vous pousse à témoigner aujourd’hui.
A : un jour, j’ai mal préfixé une branche, j’ai mis “ops/” au lieu de “sys/”, je ne savais pas, j’étais désorienté. Tous mes collègues m’ont raillé. Cela fait maintenant deux semaines, et les blagues continuent de fuser dans l’open space, ma PR n’est pas mergée, et je fais même des cauchemars la nuit.
Malgré un système en apparence rodé, Antoine a donc douté du domaine concerné. Même si nous avons appris par la suite que sa PR avait malgré tout été mergée, un suivi psychologique a été mis en place par la même occasion ainsi qu’une rééducation au nommage de branches.
L’expertise Brouette-Labs
Tous ces problèmes, nous y avons été confrontés chez Brouette-Labs, et nous avons trouvé le système infaillible. Il subsiste quelques failles néanmoins.
Le ticketing
Comme toute société reconnue, nous utilisons un système de ticketing, afin de tracer les choses. En l’occurence Jira. Mais cela peut être bien sûr trello, github, gitlab, redmine, mantis ou un excel. Chaque ticket comporte en général son identifiant, son ID. C’est la base de la résolution du problème. Ce ticket est écrit par un PO, donc il est forcément bien rédigé. En effet, on attends pas d’un dev de savoir écrire mais de savoir développer.
Voyons comment nous pouvons appliquer ce ticketing au reste du process.
Le nommage de branche
Plus besoin de se prendre la tête, prenez le numéro de ticket prefixé de l’outil utilisé, chez nous :
$ git checkout -b JIRA-32
Le nommage de commits
Plus besoin de se prendre la tête, prenez le numéro de ticket préfixé de l’outil utilisé, chez nous :
$ git add . && git commit -m "JIRA-32"
Nous avons même créé une commande gjira {id} ce qui nous simplifie le travail.
J’avais anticipé votre question, qu’en est-il s’il y a plusieurs commits ? Il y a un deux écoles, et une même solution que je vais vous montrer en exemple (exemple issu de la rédaction article).
Méthode 1 (dite “tmp”)
Vous faites votre premier commit qui respecte la convention décrite ci-dessus. Puis pour tous les commits suivants sur cette branche, vous faites les commandes suivantes :
$ git add . && git commit -m "tmp"
Cette méthode est personnelle, j’ai même créé une commande gtmp, qui me simplifie le travail. Le travail est très clair, en approuve cette capture d’écran :
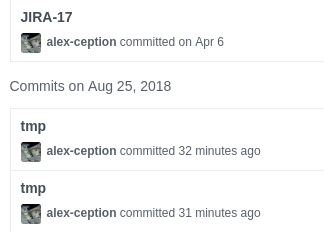
On ne parlera pas du fait que j’ai mis quatre mois à écrire cet article.
Méthode 2 (dite “copypasta”)
Vous réutilisez la technique de base, à savoir le :
$ git add . && git commit -m "JIRA-{ID}"
Une méthode également employée, mais plus redondante dans le sens où il faut à chaque fois taper l’ID du ticket :
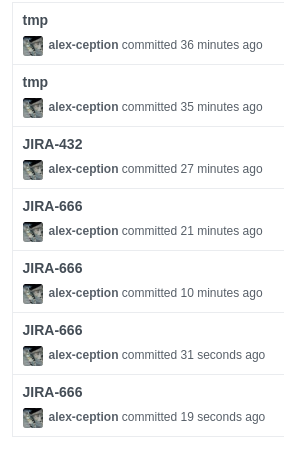
tmp ou copypasta ?
Une question que l’on peut se poser. Méthode 1 ou méthode 2. Pour ma part je préfère utiliser la méthode 1 que je trouve beaucoup plus lisible, c’est une question de goûts et de facilité avant tout, je n’ai pas toujours le numéro du ticket en tête.
Dans tous les cas, pensez à bien squasher vos commits !
Conclusion
Cet article touche à sa fin, il reste cependant un problème que je n’avais pas anticipé, plusieurs tickets dans une seule branche étant donné que le travail n’a pas été découpé comme il faut. Je ne sais pas encore comment étudier le problème. Je pense ne pas squasher pour garder l’historique des tickets pour cet article.